
RnD Café ☕️ – #348
4 mai 2024
| 📌 Sommaire L’édito L’IA au service de la business intelligence ? Brèves : Linkedin lance son offre pour les PRO Pourquoi le SEO Technique est-il important ? 8 avantages de WhatsApp pour votre stratégie marketing B2B : « Product Market Fit » mais encore ? Samedi 04 mai 2024 L’édito #348 Une petite pause s’impose ? C’est un peu le sentiment cette semaine devant le flot ininterrompu d’informations liées, une fois de plus à l’IA. C’est aussi un peu le sentiment face à toutes ces annonces qui rendent de plus en plus complexe le choix des briques technologiques, ces fameux LLM (Large Language Model dont fait partie ChatGPT), à mettre en œuvre sur vos POCs (Prototypes) en cours de développement. Comme le rappelle Alex Wang, choisir le bon modèle de traitement du langage implique de trouver un équilibre entre puissance, rapidité, coût et complexité au regard de l’usage prévu. Et quand on voit un graphique comme celui-ci qui recense les différents modèles à fin mars,… oui… c’est vertigineux ! 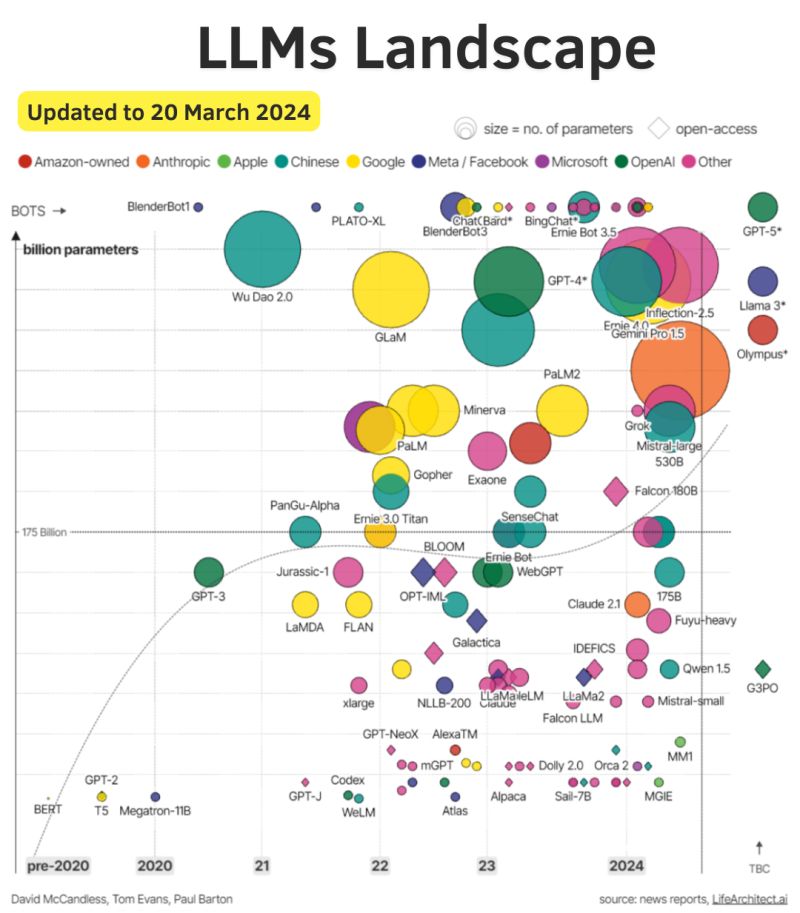 Raison de plus pour faire une pause (probablement de courte durée) et continuer à se poser les (bonnes) questions. Premièrement, une pause sur le sujet de la DATA. Au risque d’enfoncer un portail ouvert, sans data, pas d’IA. Comme le rappelle, Oliver Molander, dès 2021, l’IA était centrée sur la qualité des données plutôt que sur le développement de modèles. Mais avec l’arrivée de la déferlante ChatGPT, c’est un peu passé à la trappe. Pourtant, on y revient. Des petits modèles comme Phi-3 (Microsoft) peuvent surpasser les plus grands grâce à une meilleure sélection de données en amont. Aujourd’hui, c’est la capacité à personnaliser les LLMs avec des données spécifiques qui devient cruciale pour exploiter pleinement l’IA. Donc on fait une pause, et on nettoie sa data. Ce ne sera pas du temps perdu.  Ensuite une pause sur les questions éthiques qui nous impactent, et encore plus demain nos publics qui décideront ou non d’utiliser les outils que vous/nous leur proposerez(ons). Plusieurs voix, cette semaine, s’interrogent à juste titre sur l’impact de ces développements sur notre société. C’est le cas de Loïc Chabrier qui pose les bonnes questions en partageant plusieurs sources traitant des questions sociales (The Conversation, Le CNRS, Le Monde, La Croix), et environnementales (Ekwateur). Julien De Sanctis est un philosophe et chercheur français spécialisé dans l’éthique appliquée à la robotique interactive. Son papier cette semaine dans “Mais où va le web ? P(a)nser le numérique” est encore plus direct et critique. Indéniablement à lire pour se forger ses convictions. Vu dans la veille d’Emmanuel Vivier, Shubham SHARMA rapporte cet exemple US d’un automate prenant les commandes dans un fastfood (autre test par le Wall Street Journal ici) ce qui l’amène à prédire que nous allons assister à une augmentation des interactions humaines simples remplacées par l’intelligence artificielle, principalement pour des raisons de coût. Une interaction avec l’IA coûte environ 0,05€, soit sept fois moins qu’une interaction humaine (voir son calcul ici). Ce changement marquerait le début d’une transformation majeure dans plusieurs secteurs : Santé : Diagnostics préliminaires. Éducation : Évaluations et apprentissages personnalisés. Ressources Humaines : Préfiltrage des CV. Commerce : Automatisation des caisses et des ventes, déjà en place mais qui s’accélérera. Centres d’appels : Filtrage des demandes. Comptabilité : Saisie et réconciliation des données Et pendant ce temps-là, la technologie PRESTO qui fournit certains de ces automates serait en fait alimentée dans 70% des cas par des travailleurs aux Philippines. Merveilleux… Pour (tenter de) remédier à cette déferlante, Brian Solis, gourou du marketing digital, met l’accent sur l’importance de cultiver notre singularité. Pour lui, les compétences humaines telles que la créativité, l’imagination, l’individualité, l’esprit critique et l’empathie sont juste essentielles pour l’avenir. On est d’accord !  [pas de côté] Ce visuel me donne l’occasion de rappeler que RnD est partenaire de la Fondation pour l’Enfance, qui organise notamment les ateliers Déclic. Ces ateliers visent à sensibiliser les jeunes parents aux effets des écrans sur les petits enfants. Cette semaine, l’exécutif a pris position sur le sujet et constaté « un consensus très net sur les effets négatifs des écrans » sur les enfants. La Fondation pour l’Enfance a salué ces avancées même si elle apporte quelques bémols quant au réalisme de l’application totale des restrictions proposées pour enfants de moins de 3 ans. Nous qui travaillons dans le numérique : c’est aussi à nous de porter ce sujet. [fin du pas de côté] Dernière pause : celle sur les questions environnementales. Sur ce point, Benoît Raphaël, fidèle à son habitude, enquête minutieusement sur le (vrai) calcul de l’impact carbone de ChatGPT. Réponse complexe mais plus nuancée qu’il n’y paraît. Selon ses estimations (à prendre avec des pincettes nous rappelle-t-il), générer une image via MidJourney représenterait 23m en voiture à essence, 50 requêtes ChatGPT équivaudraient à la consommation de 0,5l d’eau. Google sortirait vainqueur sachant qu’une requête sur le moteur de recherche consommerait environ 3 à 10 fois moins qu’une requête sur ChatGPT. D’autres thèses soulignent l’impact positif de l’IA comme contributeur de solutions pour l’environnement et une poignée de chercheurs s’interrogent sur le fait que l’IA permettrait de réduire les émissions en remplaçant certaines tâches humaines. Le principe : comparer le temps passé pour écrire ou produire une image (quelques secondes pour l’IA, quelques heures pour l’humain) et le coût carbone moyen d’un humain et de son ordinateur sur cette durée. Gagnante (et de loin) : l’IA. Bref… “Ah mais pourquoi le monde est-il si compliquééééé ?” conclut-il. Pas mieux. En résumé, ces trois pauses (les données, l’éthique, l’environnement) me paraissent salutaires à ce stade si l’on en croit les questions soulevées et qui seront inévitablement posées par vos/nos publics sur les outils que vous/nous développ(ez)ons. Sur ces sujets, Ethan Mollick, dont j’ai déjà parlé ici, professeur à l’université de Wharton qui étudie l’impact de l’intelligence artificielle sur l’éducation et le monde du travail, vient de sortir un ouvrage. Co-intelligence illustre à la fois les progrès et les défis éthiques associés aux différents secteurs (Médecine, Education, Créativité, Gestion de projet, Travail, Justice). Le livre invite à la réflexion sur les changements historiques provoqués par les innovations technologiques, suggérant que les réactions initiales de peur ou de résistance face à l’IA sont comparables à celles suscitées par d’autres avancées majeures dans l’histoire. Pour autant, son conseil, avec lequel je suis très aligné, est de s’adapter et de se former pour vivre en co-intelligence avec l’IA. Côté juridique, on reparle cette semaine de RGPD (le règlement européen pour la protection des données personnelles). L’association NOYB (None of Your Business) basée en Autriche et bien connue pour ses actions en faveur de l’application du RGPD auprès de différents grands acteurs (Twitter, Apple, …) s’est attaquée cette semaine à OpenAI, l’éditeur de ChatGPT. Voir la démonstration de Luiza Jarovsky qui explique que le chatbot peut répondre n’importe quoi sur une requête sur une personne. Son argument : si le respect des droits du RGPD n’est pas réalisable pour l’IA générative, alors il ne devrait pas y avoir de sorties montrant des données personnelles ou des informations personnellement identifiables. Attention à l’entraînement de vos modèles sur ce point. L’occasion de rappeler qu’il existe des techniques de “hacking” permettant de faire “sortir” par un modèle des informations contenues dans les documents qui ont servi à l’entraîner et que les concepteurs souhaitaient garder confidentielles (sources, données privées, …). On parle de Prompt Injection. A lire chez Steve Vouilloz. Juridique toujours : quelques mots sur la propriété intellectuelle. Huit grands journaux américains, dont le NY Daily News, le Chicago Tribune, le Denver Post et le San Jose Mercury News, ont formé une coalition pour poursuivre OpenAI (dure semaine) et Microsoft. Ils les accusent d’utiliser illégalement des millions d’articles protégés par le droit d’auteur pour entraîner des chatbots tels que ChatGPT et Copilot. On comprend mieux les récents partenariats signés par OpenAi avec le FT, Le Monde, El País pour endiguer ce sujet. Pour Frédéric Filloux dans sa dernière newsletter, “les opérateurs d’I.A. continuent de clouer le cercueil des médias” : “Séduits par un gain à court terme, les éditeurs risquent de créer une concurrence létale” Côté Acteurs Semaine difficile pour Microsoft, attaqué par NOYB (👆), et déréférencé dans une administration de plus de 30000 personnes dans un land allemand au profit de l’open source et au motif d’un objectif de plus grande autonomie, de transparence et de réduction des coûts. Explications chez Konvergo. Mais les problèmes ne viennent pas que d’Europe. Sur leur propre sol, l’ancien directeur de la politique cyber de la Maison Blanche, AJ Grotto, a exprimé des préoccupations graves concernant le rôle de Microsoft au sein du gouvernement fédéral américain. Selon lui, le contrôle exercé par Microsoft sur les technologies de l’information représente un « problème de sécurité nationale« , notamment à cause de ces récents échecs en matière de cybersécurité. Vu chez Souveraine Tech. L’open source est-il un bon choix financier ? Allez poser la question à Meta qui favorise (et tant mieux) ce choix avec leur LLM Llama3. Leur cours a chuté de 15% (revenu à -8% hier) après l’annonce de leurs résultats pourtant excellents la semaine dernière. Explications : les marchés sont effrayés par le coût croissant des investissements dans l’IA. Il se trame bien quelque chose du côté d’Apple qui selon Reuters serait en pleine négociation avec Google et OpenAI. Avant que leurs développements internes sur des modèles de langage plus économes et autonomes (pour être embarqués dans un iPhone) ne soient finalisés, il est probable qu’Apple annonce le remplacement de notre cher et pathétique Siri lors de leur prochaine conférence Worldwide Developers Conference (WWDC) le 10 juin. OpenAI suscite la curiosité. Jérôme COUTOU s’interroge : “Et si ChatGPT 5 (ou 4.5) sortait avant les conférences de Google et d’Apple”. D’autres observateurs sont du même avis. Sam Altman, le PDG d’OpenAi, l’affirme lui-même : « GPT-4 est le modèle le plus stupide qu’aucun d’entre vous n’aura jamais à utiliser à nouveau. » Et sur la thématique de la recherche, même présupposé. OpenAI pourrait être tenté de couper l’herbe sous le pied de Google dont la traditionnelle conférence des développeurs avec son lot d’annonces a lieu mardi 14 mai. Le domaine (non actif à ce jour) search.chatgpt.com serait ouvert le 9 mai et la nouvelle page d’accueil d’OpenAI, suggestive s’il en est, a été mise en ligne jeudi (👇)… Sur ce sujet, très bon article déniché dans la newsletter de Laura Bokobza sur le fait que Google n’aurait peut-être pas eu besoin d’OpenAi pour tuer la recherche mais que certains choix financiers auraient déjà porté préjudice de manière fatale à l’expérience utilisateur.  Et côté usages ? Si vous avez besoin de chiffres pour vos présentations sur l’IA, en voici 149 sur son adoption dans différents secteurs issus d’une étude auprès de 4000 digital marketers du monde entier. Exemples (+ autres chiffres ici): 35% des entreprises ont adopté l’IA. D’ici à 2025, l’IA pourrait supprimer 85 millions d’emplois mais en créer 97 millions, soit un gain net de 12 millions d’emplois. 50% des consommateurs sont aujourd’hui optimistes à l’égard de l’IA. D’autres chiffres nous viennent de The Verge qui a mis à jour son étude annuelle aux US. Si vous vendez un service en indiquant qu’il a été boosté à l’IA, 53% des millénials, et 49% des GenZ seront plus intéressés a priori ! 61% de ces derniers préfèrent d’ailleurs utiliser l’IA plutôt que Google pour leurs recherches (malgré les risques de désinformation). D’autres analyses ici par Nicolas Guyon En France, son de cloche un poil différent ! Le BCG a publié une étude il y a une semaine qui met en lumière que 31% des Français se disent préoccupés de l’utilisation de l’IA, faisant de la France le pays le plus pessimiste sur le sujet. Sur les métiers du marketing, le magazine Stratégies témoigne du fait que l’IA générative transforme le marketing, et qu’elle est comparée à l’avènement du web. Selon LinkedIn, 67% des décideurs augmenteront son usage en 2024. Les entreprises explorent cette technologie, distinguant les utilisateurs avancés et ceux plus frileux et préoccupés par la sécurité des données, les “hallucinations”, les débats éthiques, autant de sujets complexes (cf. nos trois pauses en amont☝️). Leur conclusion : “Y aller et voir, c’est à peu près tout ce que l’on sait”… Sur les métiers des ressources humaines, la conférence People Analytics World qui vient de se tenir à Londres est une somme de ressources sur cette discipline organisationnelle qui consiste à appliquer des méthodes scientifiques et statistiques aux données comportementales des collaborateurs. Très riche article ici. On y apprend entre autres que selon Gartner, les travailleurs indépendants représenteront 35 à 40 % de la main-d’œuvre mondiale d’ici 2025.  Et sur le déploiement de l’IA dans l’entreprise ? Ce schéma, issu de ce post, résume bien les trois étapes à suivre selon Burak Bakkaloglu. 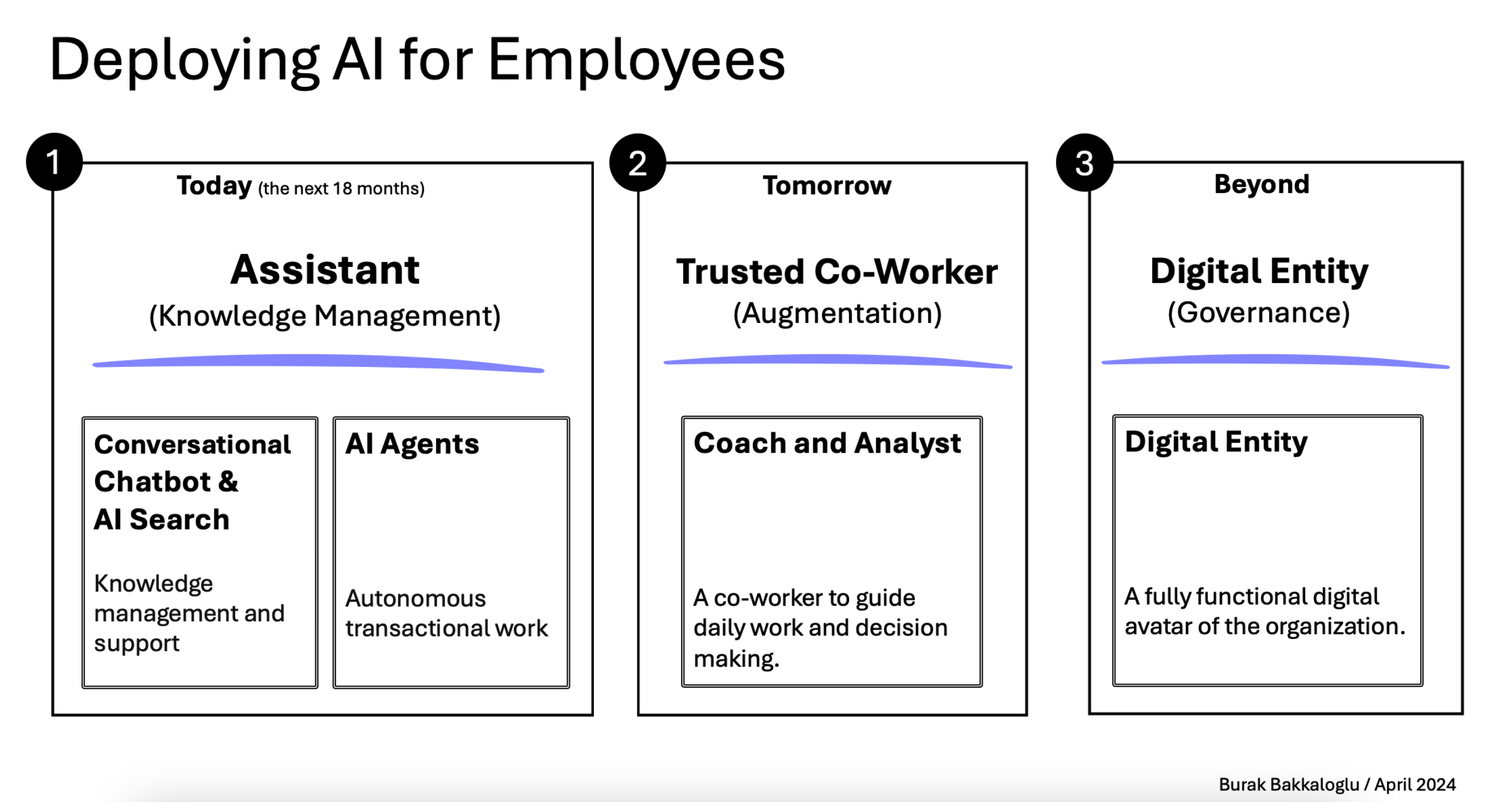 Dans les autres secteurs, c’est toujours un peu la course aux cas d’usages. Deux ressources cette semaine sur ce point avec le rapport du MIT Technology Review Insights et de Databricks et la base de données de 101 cas rassemblés par Google. Pêle-mêle (en plus de ceux vus plus haut) : Juridique : Automatisation de la rédaction de contrats standards via des paramètres utilisateurs. Banque : Utilisation de chatbots pour comprendre et répondre aux requêtes en langage naturel et effectuer des opérations simples. Énergie (Shell) : Extraction d’informations de documentation technique non structurée. Santé : Génération automatique de rapports médicaux pour permettre aux praticiens de se concentrer sur les soins. Voir d’ailleurs l’annonce de Med Gemini de Google, une version de chatbot qui appuie le médecin. Et d’autres résumés ici. Puisque nous avons parlé de formation, je continue à partager les ressources que je trouve les plus claires possibles pour comprendre ce qui se cache sous le capot de l’IA en mode “ne pas sous-traiter sa compréhension du sujet”. Tout d’abord ce très bon récap des différents composants de l’IA vu chez François Guité (il n’y a pas que l’IA générative dans la vie). 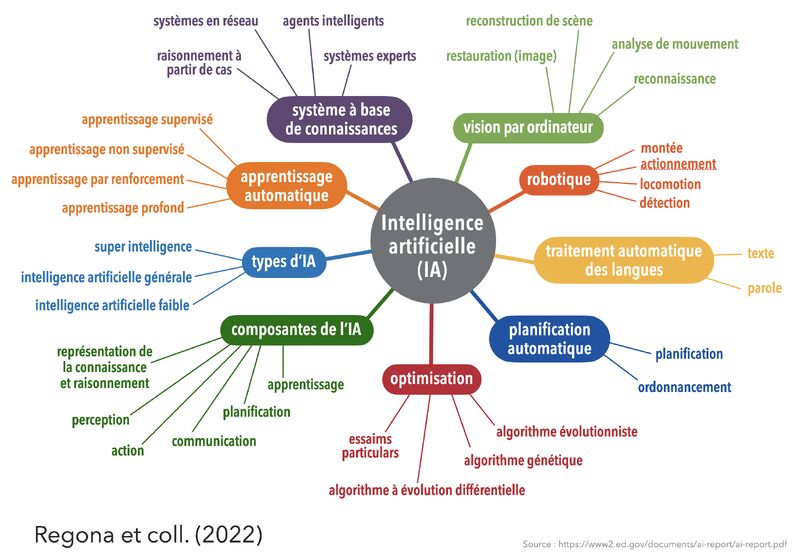 Puis cet article hyper pédagogique sur fonctionnement de ChatGPT en 5 étapes expliqué par ses concepteurs : Entrée : Réception du texte utilisateur. Tokenisation : Découpe du texte en tokens, similaires à des mots. Création d’embeddings : Transformation des tokens en vecteurs numériques. Multiplication par les poids du modèle : Les embeddings sont multipliés par les poids du modèle. Échantillonnage de la prédiction : Le vecteur résultant prédit le token suivant, générant la réponse de ChatGPT.  Pour finir (et bravo d’avoir tenu jusqu’ici), voici un cas d’usage qui rend optimiste avec IRIS, premier agent conversationnel au monde, capable de communiquer en langue des signes (version française, québécoise, américaine et tunisienne), et développé par IVèS. Clairement une amélioration de l’autonomie et la participation sociale des personnes sourdes et malentendantes, cet avatar est déjà déployé sur plusieurs sites dont celui d’Orange. Laurie Zingaretti parle de design inclusif.  Je parlai de faire une pause au début de ce numéro. Le RnD Café en fera aussi une la semaine prochaine, aqueduc oblige. Nous nous retrouverons donc le samedi 18 mai. D’ici là, portez-vous bien et bon week-end. A retenir cette semaine L’IA au service de la business intelligence ?  Lors des ateliers KPI et dashboards que nous animons, c’est clairement devenu un sujet récurrent : comment simplifier l’accès à la data ? Simplifier, non pas seulement au sens technique, mais également au sens organisationnel et bien sûr en termes de lisibilité. Explications Au sens technique (cf. l’édito), cela suppose principalement des réponses à ces questions : Quelles sont les sources ? Sont-elles accessibles ? Sont-elles fiables et normalisées ? Dès lors apparaît immédiatement un premier sujet : comment centraliser des datas provenant de diverses sources dans un même tableau de bord ? C’est le point clé de ce que l’on appelle la Business Intelligence et de la sous partie qui nous occupe ici : les Web Analytics. Important donc de ne pas se contenter de GA4, Matomo, Piano et consors. Au sens organisationnel, on parle ici d’autonomie. Je suis frappé du nombre d’interlocuteurs au marketing, aux rh, dans les directions qui dépendent d’un service tiers pour accéder à des données nécessaires à leurs missions. Avoir besoin d’un data scientist ou d’un développeur pour faire une requête pour tenter de comprendre un phénomène précis, soit. En avoir besoin pour extirper les indicateurs clé pour prendre des décisions, non ! Car c’est bien de cela qu’il s’agit. Le sujet n’est pas de créer un énième reporting. Le sujet est de créer un outil d’aide à la décision accessible en toute autonomie 24/24 7/7. Nous en venons au troisième point ; la lisibilité. Bien sûr, nous avons tous en mémoire l’adage selon lequel « trop d’indicateurs tuent l’indicateur« . Et pourtant. Un dashboard pour un comité de direction n’est pas le même que pour l’équipe digitale chargée de l’acquisition. Pour le premier, un format A4 recto verso devrait être un maximum avec un focus sur les indicateurs de performance uniquement. Pour le second, une analyse par canal / par campagne est nécessaire, c’est-à-dire avec un prisme sur les indicateurs de moyen (et pas uniquement de performance) : “est-ce que le moyen que je mets en place pour atteindre mon objectif est efficient ?” Et c’est là que la lisibilité est un sujet. L’Intelligence artificielle est-elle une réponse ? Dans l’une des récentes newsletters de Magma, outil de veille, ce point a été abordé. Une étude du cabinet Gartner de mars dernier lance un constat sans appel : moins de la moitié des équipes chargées des données et de l’analyse apportent une valeur ajoutée aux organisations. En cause : la prolifération des données associée à la complexité grandissante des outils. Deux pistes à explorer selon Magma. un ChatGPT des analytics : on instaure un “dialogue” avec ses données en posant des questions et l’outil répond de manière immédiate. Acteur à suivre : Fluent (UK). la visualisation graphique des données avec par exemple, Julius, un outil de BI (Business Intelligence) américain qui peut analyser et visualiser des données complexes de manière intuitive et conviviale. Cet outil rend l’analyse de données accessible à tous, même aux non-experts. Ce qui est nouveau, c’est l’idée que la plateforme puisse automatiquement convertir les analyses complexes en récits visuels interactifs. Cette approche narrative pourrait révolutionner la façon dont les entreprises communiquent les résultats de leurs analyses de données, en rendant les rapports plus captivants et engageants. 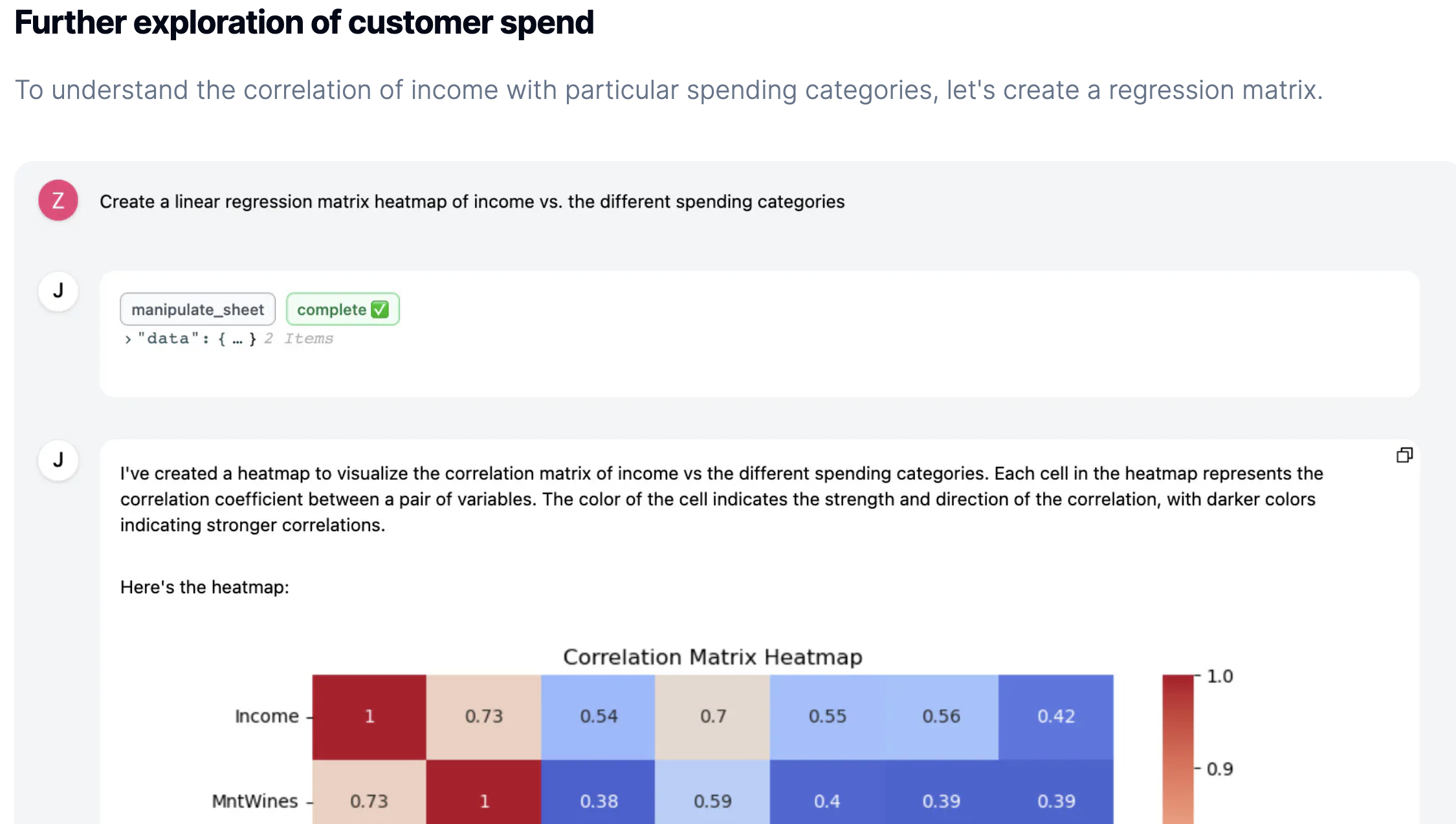 A suivre. Vous avez besoin d’échanger sur vos On en parle quand vous le voulez. En bref (ou presque) 🔆 Linkedin lance son offre pour les PRO LinkedIn dévoile un nouvel abonnement payant pour les Pages Entreprise, mettant en avant différentes fonctionnalités dont un bouton d’appel à l’action personnalisé ou encore une assistance IA pour la rédaction de vos contenus. Découvrez en plus dans cet article d’Alexis Lemonnier. 📌 Pourquoi le SEO Technique est-il important ? Pour les plus curieux d’entre vous, découvrez cette étude émanant d’un outil de supervision du SEO Tech qui recense les erreurs les plus communément identifiées sur 1 000 000 de sites étudiés. Vous seriez par exemple surpris du nombre de pages 404 (introuvables). 📲 8 avantages de WhatsApp pour votre stratégie marketing Cet article nous en dit plus sur l’élaboration d’une stratégie marketing efficace sur WhatsApp. De la définition des objectifs à l’utilisation d’outils de gestion de campagne, découvrez quels sont les avantages et les bonnes pratiques pour votre marketing : portée mondiale, marketing conversationnel, taux d’ouverture élevé… 👥 B2B : Product Market Fit mais encore ? Voici un document de référence repéré dans la NL de Laurence Bokobza qui permet de bien redéfinir ce qu’est un product market fit. Ce document est intéressant à lire et ne s’adresse pas seulement à ceux qui s’apprêtent à lancer un produit. Il est toujours utile de temps en temps de revenir aux fondamentaux. |